Understanding GPU Memory Corruption at Extreme Scale: The Summit Case Study
Jun 1, 2024·
,
,
 ,
,
·
0 min read
,
,
·
0 min read
Vladyslav Oles
Anna Schmedding
George Ostrouchov
Woong Shin
Evgenia Smirni
Christian Engelmann
Abstract
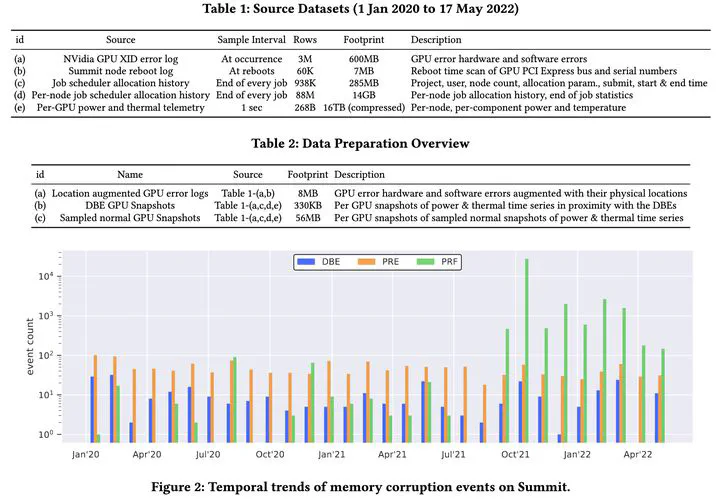
GPU memory corruption and in particular double-bit errors (DBEs) remain one of the least understood aspects of HPC system reliability. Albeit rare, their occurrences always lead to job termination and can potentially cost thousands of node-hours, either from wasted computations or as the overhead from regular checkpointing needed to minimize the losses. As supercomputers and their components simultaneously grow in scale, density, failure rates, and environmental footprint, the efficiency of HPC operations becomes both an imperative and a challenge. We examine DBEs using system telemetry data and logs collected from the Summit supercomputer, equipped with 27,648 Tesla V100 GPUs with 2nd-generation high-bandwidth memory (HBM2). Using exploratory data analysis and statistical learning, we extract several insights about memory reliability in such GPUs. We find that GPUs with prior DBE occurrences are prone to experience them again due to otherwise harmless factors, correlate this phenomenon with GPU placement, and suggest manufacturing variability as a factor. On the general population of GPUs, we link DBEs to short- and long-term high power consumption modes while finding no significant correlation with higher temperatures. We also show that the workload type can be a factor in memory’s propensity to corruption.
Type
Publication
Proceedings of the 38th ACM International Conference on Supercomputing